


模块化遥操+“选择策略”机器人“学会”全身协调
2026年04月29日
导读
人形机器人在以人为中心的环境(如家务场景)中展现出巨大的应用潜力。然而,要在如此复杂的非结构化环境中实现高效运行,机器人必须具备头部、双臂及躯干的全身协同能力,以完成对物体的主动搜索、定位、抓取与操作。当前,实现这种高度的灵巧性与灵活性仍极具挑战性,其难点在于不仅需要高度流畅的全身协同控制,更需实现运控(locomotion)与操作(manipulation)的深度融合。
目前,在解决上述问题中被广泛应用的机器学习方法(Learning from Demonstrations, LfD)在全身运控协调、模拟人类的多模态行为特征以及响应实时性上仍存在较大缺陷。
基于此,来自加州大学伯克利分校的研究团队提出了一套创新方案,即通过模块化的数据采集结合名为选择策略(Choice Policy)的机器学习方法,实现人形机器人在非结构化环境中的全身协同操作,使机器人能够实现快速推理的同时有效建模多模态行为。
研究团队在洗碗机装载以及移动擦拭白板的两个真实场景任务中对该策略进行验证,结果表明经过该方案进行学习、训练的机器人(傅利叶GR-1)在长程序列任务的执行中呈现出更高的成功率与鲁棒性。
一、研究背景
围绕人形机器人运控与操作的研究一直在进行。一种常见策略是通过关键点匹配将人类动作重定向(Retargeting)至机器人。结合计算机视觉在人体姿态估计方面的进步,该领域的研究近年来已取得显著进展,代表性工作包括:H2O、OmniH2O、HumanPlus 及 TWIST 等。然而,受限于人机自由度的差异,此类方法在重定向过程中会不可避免地引入误差,因此难以支撑高精度的操作任务。
近期的研究进一步尝试利用虚拟现实(VR)设备结合全身逆运动学解算来控制机器人,以获取更精准的姿态信息(典型方法如 Open-TeleVision、HumanPlus、AMO、HOMIE 等)。但这类方法的弊端在于,繁琐的设备配置限制了机器人全身演示数据的高效获取。
另一方面,在解决上述问题中被广泛应用的机器学习方法(Learning from Demonstrations, LfD)仍面临着表征力与时效性之间的矛盾。以扩散策略(Diffusion Policy)为代表的方法,虽然能够通过迭代采样拟合多模态动作分布,从而有效应对人类演示中的多模态特性,但其推理效率低下——多步采样过程难以满足人形机器人实时控制对低延迟的严苛要求。
与之相对,行为克隆(Behavior Cloning)方法虽能直接建立从观测到动作的映射,凭借单次前向传播实现快速推理,但其核心问题在于“多模态坍缩”:当同一观测对应多种有效动作时,以均方误差为目标的优化过程会迫使模型对不同行为取平均,导致生成的动作往往脱离实际、效果欠佳。
尽管最新的研究试图通过离散化动作空间或引入词元化表示来应对这一状况,但这些方法尚未在需要协调全身自由度的人形机器人上表现出强劲的性能。
二、新的方案思路
针对当前策略的不足,来自加州大学伯克利分校的研究团队提出一套创新性的解决方案,结合模块化遥操作接口与可扩展的学习框架——选择策略(Choice Policy),以优化在复杂长序列任务操作中,人形机器人的全身协调表现。
模块化数据采集
研究团队认为,人形机器人目前所面临的协调性问题一定程度上是由训练数据质量不佳导致的。因此,该团队首先提出了一套全新的数据采集策略——模块化策略——降低操作复杂度,提升数据质量。他们将遥操作的全身控制模块拆解为四个核心技能,并在操控手柄上设计了专用按钮,支持用户按需激活:
手部操控:采用分组协同与独立控制策略。四个非拇指手指归为一组,由抓握按钮统一驱动;拇指由摇杆独立控制。两者均输出连续值信号并线性映射至关节角度,赋予操作者细粒度运动控制与抓握力精确调节的能力。
臂端操控:为单臂操作进行优化,杜绝了空闲手臂的漂移或悬滞。支持操作者迭代式重置控制器以动态重中心工作空间,使机器人能执行大范围连续运动,无需操作者在物理空间重复肢体轨迹。
移动策略:基于Sim-to-Real 速度条件强化学习(Velocity-Conditioned RL)。策略以 100 Hz 高频运行,将参数化速度指令转化为目标关节位置,由本地 PD 控制器精准跟踪。操作员可通过 Quest 摇杆实现移动与操作模式的无缝切换。
手眼协同:引入“主动跟踪模式”。一键触发后,头部模块自动跟随左手或右手,确保摄像头持续锁定操作手,使关键区域始终位于视野中心,显著降低长程任务中的视觉遮挡风险。

四个核心技能模块
该设计还具备极高的可扩展性,允许通过子模块插件的形式无缝融合诸如手指步态(Finger Gaiting)之类的高级灵巧技能。
研究团队认为,模块化设计提供了两方面好处:首先,更低的操作复杂性使得遥操作更容易学习。在实验验证中,用户通常只需要不到10分钟的练习就能流畅地执行复杂的长程任务。其次,模块化在数据收集阶段,有效兼顾了遥操作的表征力与模型学习的灵活性。
新的学习策略-选择策略(Choice Policy)
基于上述模块化遥操作系统采集的数据,研究团队引入了选择策略。具体而言选择策略包含三个关键部分:特征编码器(feature encoder)、动作提议网络(action proposal network)与评分预测网络(score prediction network)。
在这一架构中,特征编码器负责率先将视觉输入与机器人本体感知信号进行融合,映射为统一的特征向量。随后,动作提议网络基于该特征向量,预测生成一组基于多步预测的候选动作轨迹。与此同时,评分预测网络接收相同的特征向量,对每一条候选轨迹进行评估,计算其与真实轨迹之间的均方误差(MSE),并输出对应的置信度分数。
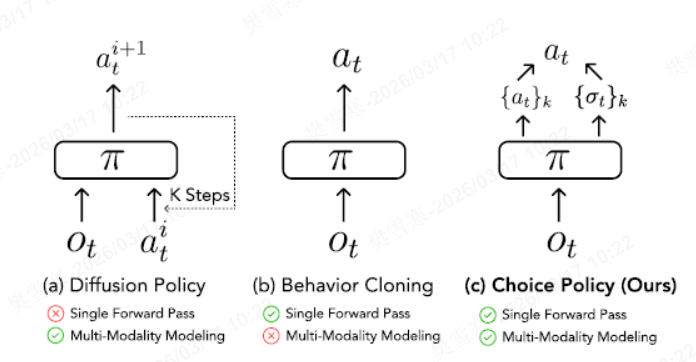
模仿学习策略的架构对比(a) 扩散策略 (b) 标准行为克隆 (c) 选择策略 (本文方法)
在训练阶段,针对策略生成的K个候选动作轨迹及其预测分数,选择策略会计算每个提议轨迹与真实轨迹at之间的均方误差,并在动作维度及预测时域上对其取平均值:
基于这一均方误差,训练过程分为两部分:
评分预测网络:直接将计算出的MSE作为回归目标,使其学会准确评估轨迹质量;
动作提议网络:采用“胜者通吃”(Winner-Takes-All, WTA)策略。团队仅筛选出均方误差最小的候选轨迹,并仅通过该最优轨迹反向传播梯度来更新网络参数。
在推理(实际应用)阶段,评分预测网络将会最终选择预测误差最低的轨迹进行执行。

选择策略训练与推理流程的 PyTorch 伪代码
在不依赖扩散模型或先验标记的情况下,该算法可捕捉演示中存在多模态行为,并鼓励动作提议网络生成多样化的候选轨迹,同时,评分预测网络可以引导模型不断逼近最优解,并通过神经网络的单次前向传播(single forward pass)实现对机器人高效的全身控制解算,使其能够快速应对对实时性要求严苛的动态操作任务。
三、实验验证
研究团队设计了两个任务对上述方案进行评估:将盘子插入洗碗机及白板擦拭,前者用于测试选择策略的有效性、遥操作系统的质量以及手眼协调的重要性,后者作为遥操作系统灵活性的验证。
任务一:将盘子插入洗碗机

GR-1进行将盘子插入洗碗机实验
在此任务中,傅利叶GR-1人形机器人需要将桌上的盘子拾起,经双手传递后,精准插入洗碗机的指定卡槽。在每次试验开始时,一个盘子被放置在GR-1面前的桌子边缘附近。GR-1必须借助桌子边缘对盘子实施抓取,抓取成功后,任务需要GR-1将盘子从一只手传递到另一只手,然后插入洗碗机内的碗碟架中。期间,GR-1必须主动调整头部以跟踪操作手。
上述任务完成后,GR-1将进一步面对不同颜色和初始位置盘子的鲁棒性测试。
为此,实验团队使用模块化遥操作系统采集了100 组演示数据,涉及GR-1上半身与手部关节的29自由度向量。
任务二:白板擦拭

Robotera Star-1机器人进行擦拭白板实验
在此任务中,白板和白板擦被放置在距离机器人一定距离的位置,位于其初始视野之外。机器人必须首先移动头部以定位白板擦,然后抓取它。成功抓取后,机器人需要向左走向白板的标记区域,并将白板上的笔迹区域擦拭干净。机器人每次任务的初始位置均为随机。
实验团队使用Robotera Star-1机器人,并使用模块化遥操作系统采集了50组演示数据。
四、实验结果与结论
任务一:将盘子插入洗碗机
【对比视频】https://choice-policy.github.io/
实验团队对比了分别使用选择策略、行为克隆及扩散策略训练的GR-1在任务成功率方面的表现,测试结果显示:
拾取阶段:三种方法均表现出较高的可靠性;
传递与插入阶段:行为克隆与扩散策略训练的GR-1在面对多模态决策时表现欠佳。在双手传递环节,二者成功率仅为70%;而在难度更高的洗碗机插入环节,成功率进一步跌至50%;
选择策略训练的GR-1在整个任务序列中保持了卓越的稳定性。其将双手传递的成功率提升至90%,插入环节的成功率大幅提高至70%。
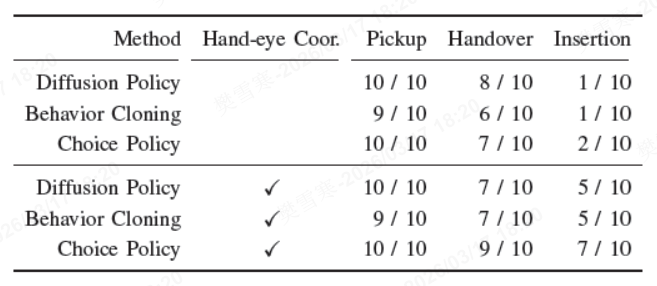
在将盘子插入洗碗机实验中选择策略、行为克隆及扩散策略的性能表现
将盘子替换成与训练时不同的颜色,并放置在略微超出训练范围的位置后,测试结果显示:
所有算法训练的GR-1在任务成功率方面均有所下降;
选择策略训练的GR-1在拾取、交接和插入阶段的成功率均相对更高,对于未进行训练和颜色和目标位置显示出相对更强的鲁棒性。
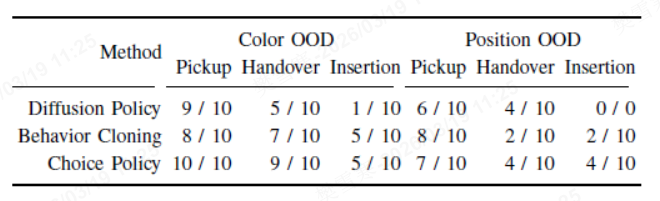
在将盘子插入洗碗机实验中选择策略、行为克隆及扩散策略的鲁棒性表现
任务二:白板擦拭
由于推理速度慢且训练不稳定,实验团队无法使用扩散策略用于白板擦拭任务的机器人学习,对比选择策略、行为克隆,结果如下:
行为克隆与选择策略均能成功完成头部移动;
选择策略训练的机器人在抓取白板擦、移动可靠性和擦拭成功率上表现更优;
行为克隆训练的机器人常因最终定位不准导致擦拭失败;
尽管成功率有限,借助模块化遥操作系统收集的数据以及选择策略的训练,人形机器人可以协调全身,成功执行个别具有挑战性的长序列操作任务。
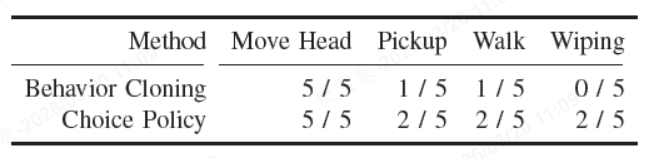
在白板擦拭实验中选择策略、行为克隆的鲁棒性表现
综上,经模块化的遥操作系统和选择策略训练的人形机器人在长序列高难度操作任务中的执行中表现出更高的成功率和更强的鲁棒性,继而证明,研究团队所提出的方案在实现复杂长序列任务操作中的人形机器人协调控制方面起到作用。
同时,研究团队也进一步认为,该策略仍存优化空间:首先,方案中的视觉感知组件在面对陌生场景或异构物体时,泛化性能有限。未来将致力于引入更多样化的训练数据,或利用大规模数据集进行预训练,以进一步提升方案的鲁棒性。
其次,目前方案中的手眼协调策略主要依赖将头部视线锁定于活动手。未来将探索更具自适应性的学习机制,以替代现有的固定规则,从而进一步优化机器人在动态环境下的交互性能。
论文链接:https://arxiv.org/abs/2512.25072
傅利叶支持并推动具身智能的研究探索,通过与全球最头部的科技公司和顶尖科研院校开展交流与合作,加速人形机器人技术的创新与应用,促进AI与物理世界的融合发展。
Contact Us
生态合作:generalrobot@fftai.com
人才招聘:job@fftai.com

