导读
相比轮式和履带式的机器人,足式机器人在应对复杂地形方面具备更大的潜力。然而,要实现其在多样地形的 “精准、稳健、通用” 运动控制,仍是一个尚未彻底解决的挑战。为此,研究人员已探索了多种方法。
现有方法中,传统的基于模型控制的算法(如MPC)在特定复杂地形的规划表现良好,但在面对不确定环境时缺少泛化性,无法适应各种各样的真实场景。相比之下,基于学习方式的算法(如DRL)克服了这一问题,面对不确定展现出较强的抗干扰能力,但在面对崎岖狭窄地形时,难以准确规划落脚点。混合式方法(如DTC)试图结合两者优势,提升控制器在崎岖地形的鲁棒性,但计算成本高,且受限于模型控制方法自身的局限性,训练耗时较长。
为突破这些瓶颈,苏黎世联邦理工学院(ETH Zurich)机器人系统实验室和迪士尼苏黎世研究中心联合提出了基于注意力地图编码的框架,结合端到端强化学习,为足式机器人在多样化地形的运控问题提供了新的解决思路。

基于注意力地图编码框架
由联合研究团队共同提出的基于注意力地图编码框架结构包含两个层级:卷积神经网络(CNN)与多头注意力机制(MHA)。
在框架结构上,底层用卷积神经网络(CNN)从 2.5D 地形数据中提取局部特征(如高度、结构关系),为判断 “可落脚点” 提供基础。再通过多头注意力机制(MHA),结合机器人本体感知数据(如关节角度、速度)对地形特征分配注意力权重,自动筛选关键地形点并规划潜在落脚点,形成紧凑且泛化性强的观测表示。根据研究团队观察,这些被选中的点在无需监督学习的前提下,即可自发为机器人规划出潜在的落脚点位置。
为了更高效地将采集的数据、特征与模型和控制策略相结合,制定有效的机器人运控策略,研究团队又针对性的设计了两阶段训练流程:
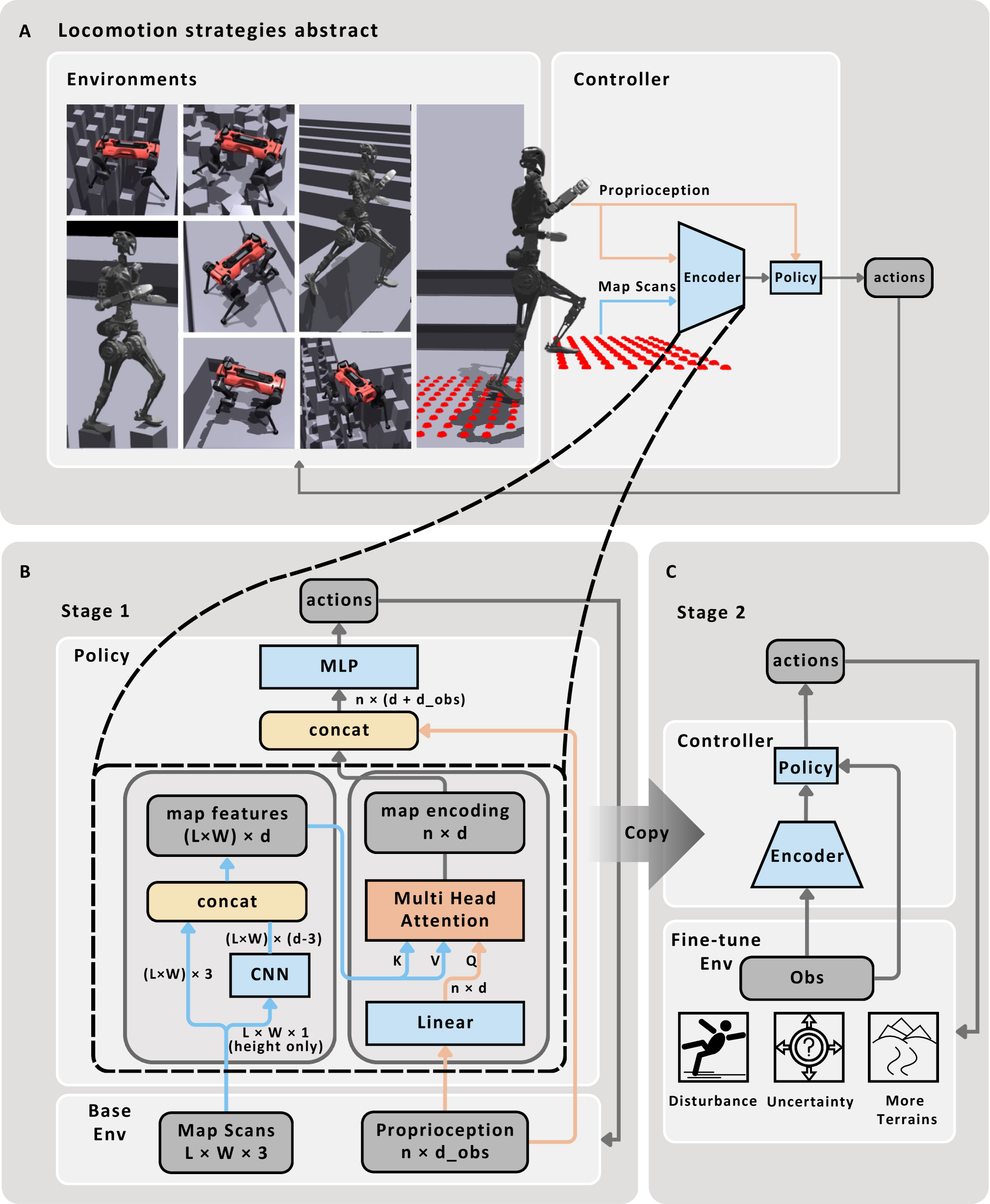
两阶段训练流程的可视化
实验结果
研发团队随后将该学习策略分别部署在傅利叶 GR-1 人形机器人和 ANYmal-D 四足机器人狗上进行测试,训练机器人克服独木桥、点桩、越障等极限地形行走。实验结果表明,部署该策略的机器人在复杂地形的泛化移动上展现出良好的精准控制和鲁棒性。
1. 精确性与泛化性
部署该策略的机器人在穿越未经训练过的地形时,成功率达到 100%。,GR-1成为首个通过在线控制器,在崎岖复合路面地形进行动态行走的人形机器人。对比 DTC 和基线 RL,团队提出的基于注意力机制的学习框架速度跟踪误差更低(高速度指令下优势显著),各地形成功率平均高出 26.5%(DTC)和 77.3%(基线 RL)。
2. 灵活性和稳健性
该策略在真机上同样展现出了出色的灵活性与鲁棒性。通过学习全身运动控制,GR-1能主动协调运用膝关节和手臂来提升灵活性。在面对打滑或者站不稳时,机器人可以通过摆臂幅度和频率,动态调整,恢复平衡。最令人印象深刻的是,部署了该策略的 GR-1 甚至能在单个木桩上完成单腿换跳来跨越隔断,成功跃上下一个落脚点。

GR-1穿越分散障碍物、打滑后快速调整
3. 速度适应性
研究团队还尝试了在复杂地形上,以不同速度指令控制GR-1。例如让GR-1在一排高低不平的石墩或晃动的平衡木上行走,触发不同的步态模式和全身协调动作。这种多样化的运动能力,能够大幅拓展机器人在复杂地形和狭小空间的作业适应范围。

速度指令从0.7m/s变为1.5m/s时,GR-1 步幅更长
4. 仿真环境中的性能测试
与DTC、基线RL的比较测试:研发团队以速度跟踪、训练地形及单个地形的成功/失败/卡住率为标准,将基于注意力机制的学习策略与DTC、基线RL等其他三种控制器的表现状况放在仿真环境中进行对比。测试结果显示,该策略的速度跟踪误差更低,在全地形挑战中较 DTC 的成功率高26.5%、较基线RL高77.3%。
两阶段训练消融研究:研究团队还专门就两阶段训练流程(基础地形真实观测初始化+全地形加噪声微调)的必要性进行了验证。他们在仿真环境中模拟出经过两阶段训练的第一个控制器,和另外两个对照组控制器C2和C3。其中C2是直接在所有地形用真实观测从头训练的控制器,未经过 “基础地形初始化” 阶段;C3则是直接在基础地形加传感器漂移和噪声从头训练的控制器,未经过 “全地形微调” 阶段。结果表明,经过两阶段流程训练的运控策略在几乎所有地形的测试成功率均高于C2和C3。
网络结构消融研究:最后为验证基于注意力的地图编码结构中低层CNN+MHA模块的有效性,研究团队将其与另外三种替代结构(CNN+Transformer、下采样CNN、视觉Transformer)分别在仿真环境中进行了对比。结果显示,本文结构训练收敛等级更高,部署成功率更高,尤其在未见过的地形上泛化性更优,验证了该结构的有效性。
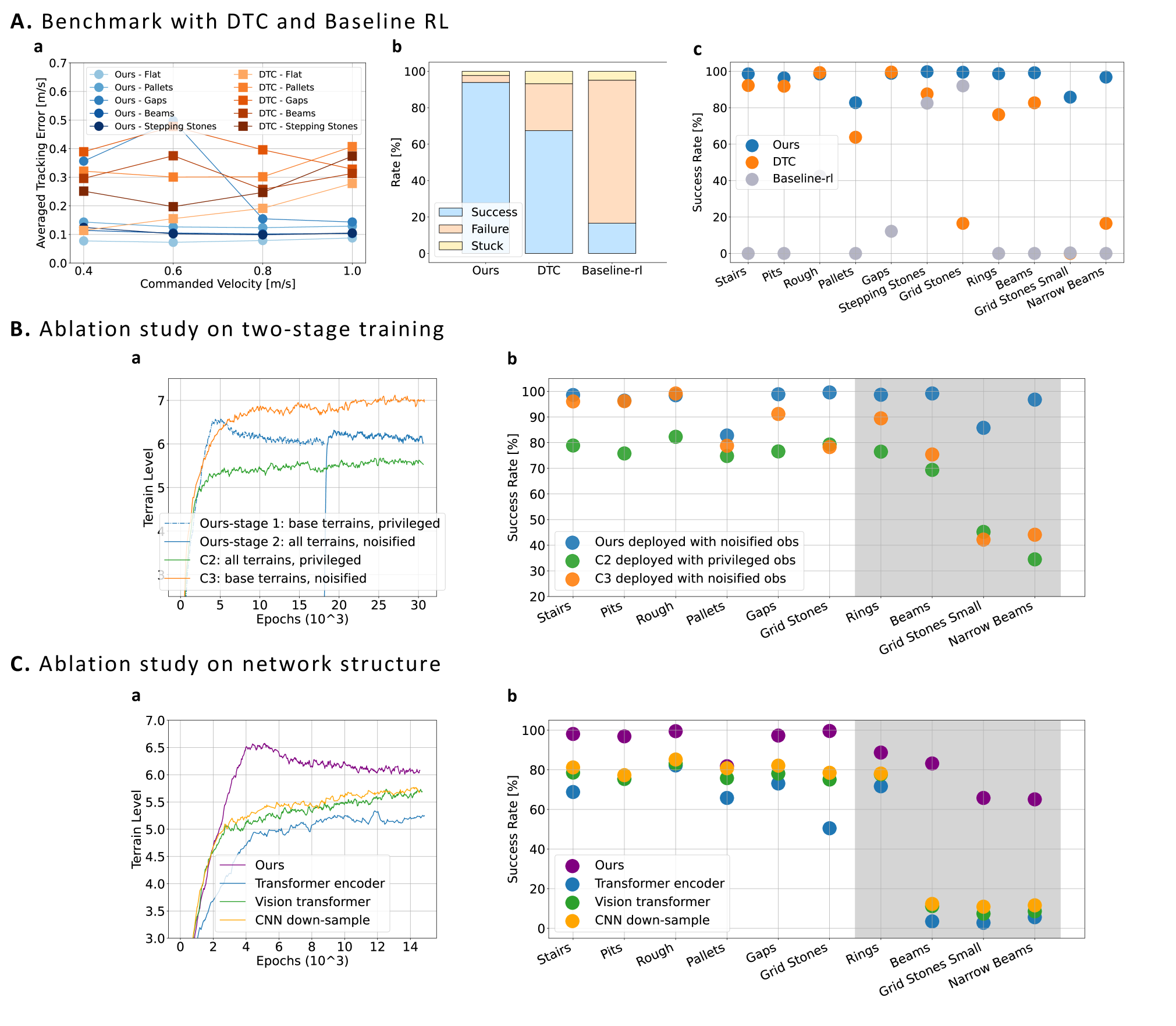
基于仿真的综合评估结果,研究团队训练方法具有优势
为了进一步阐明基于注意力的地图编码所具备的可解释性,研发团队对多种不同类型地形下,MHA 模块的注意力权重分布进行了详细可视化展示。
图A显示,第二阶段微调后的控制器在混合地形上,MHA 模块注意力权重集中于下一个可踏区域;
图B体现,第一阶段训练中,机器人在网格石等地形上响应不同命令时,MHA 会依据运动学和动力学特征,将注意力集中到支撑立足点的关键区域,甚至能拒绝不可行命令;
图C表明,第一阶段控制器对未见过的地形(如五边形石头等),注意力分配合理,体现出泛化能力。
这些可视化结果表明,模型能根据本体感受信息和命令方向动态调整关注焦点,支持了 MHA 模块可增强复杂运动任务的可解释性和泛化能力的结论。

注意力权重可视化,红色强度越高表示注意力权重越大
结论
该研究首次在保持强化学习控制器鲁棒性的前提下,实现了具备泛化能力的足式机器人动态行走。此前,类似的泛化性多见于依赖模型规划的四足机器人控制器,而ETH与迪士尼苏黎世研究中心的联合研究团队证明了通过深度强化学习同样可以达到可比拟的性能,同时规避了模型规划方法在不确定性和建模误差条件下的局限。
值得一提的是,该策略网络设计在功能结构上呼应了模型规划方法的模块化思路:地图编码模块通过注意力机制隐式筛选未来落足点,类似于接触点规划器(contact planner);而后续策略部分则像全身控制器,追踪已规划的接触点。但不同于传统分布式控制方式,研究团队将整个控制流程端到端集成,通过数据驱动的方式,解决了模型规划方法计算负担重、建模偏差和假设前提易被打破的问题。同时,也便于整体优化调参,降低系统复杂度。
但不可忽视的是,该策略同样存在一些局限性。首先,策略训练过程耗时较长,通常需要数天时间,且由于训练代价较高,参数调优的效率也受到限制。其次,当前采用的2.5D高度图作为环境表示形式在一些特殊场景(如狭小空间)下可能不适用。第三,该研究聚焦于机器人行走能力,而手臂的操作功能尚未纳入整体控制框架,尚未探讨如何在行走与操作任务之间合理协调手臂动作需求。
未来,研究团队还将继续探索:
论文链接:Attention-Based Map Encoding for Learning Generalized Legged Locomotion
傅利叶支持并推动具身智能的研究探索,通过与全球最头部的科技公司和顶尖科研院校开展交流与合作,加速人形机器人技术的创新与应用,促进AI与物理世界的融合发展。
Contact Us
生态合作:generalrobot@fftai.com
人才招聘:job@fftai.com




