


英伟达 x UCB:最新视觉灵巧操作研究,突破人形复杂接触式任务上限
2025年05月23日
导读
想象一下,训练机器人执行物品移交任务时,可能会遇到哪些插曲?
物体形状、大小、质量等属性复杂多样,机器人无法完全还原真实差异,抓取难免“翻车”;
现实环境感知存在噪声,易受到多种因素影响,与仿真环境间隔“次元壁”;
传统的强化学习方法在灵巧操作任务中表现不佳,高维度空间探索难以制定合理有效的奖励机制,机器人自主学习能力无法“觉醒”。
要想实现机器人在现实环境中灵活运动,需要它们与环境不断交互试错学习。但科学家这次选择——让机器人在虚拟世界“升级打怪”,再把技能无缝衔接到现实中,不用人类示范,就能让机器人的“双手”拥有接近人类的灵巧度。
日前,英伟达(NVIDIA)、加州大学伯克利分校(UC Berkeley)、德克萨斯大学奥斯汀分校(UT Austin)的实验室研究团队针对基于视觉的人形机器人灵巧操作实践提出了一种更优化的从仿真到现实的强化学习策略方法。
研究团队将优化后的强化学习策略部署在配备多自由度灵巧手的傅利叶GR-1人形机器人,训练其完成一系列高接触、复杂交互的灵巧操作任务。测试机器人的感知输入分别来自一个第三视角摄像头、由机器人自带的第一视角摄像头及机器人本体关节和力传感器。实验结果证明,经过该方法训练过的机器人能够应对真实环境中多种未见过的物体,并适应其不同的物理特性(形状、尺寸、材质、质量等)。同时,部署该学习策略的机器人还能在有一定外力干扰的情况下保持稳定操作。这为人形机器人在真实动态环境中的复杂任务执行提供了更强泛化性与鲁棒性保障。
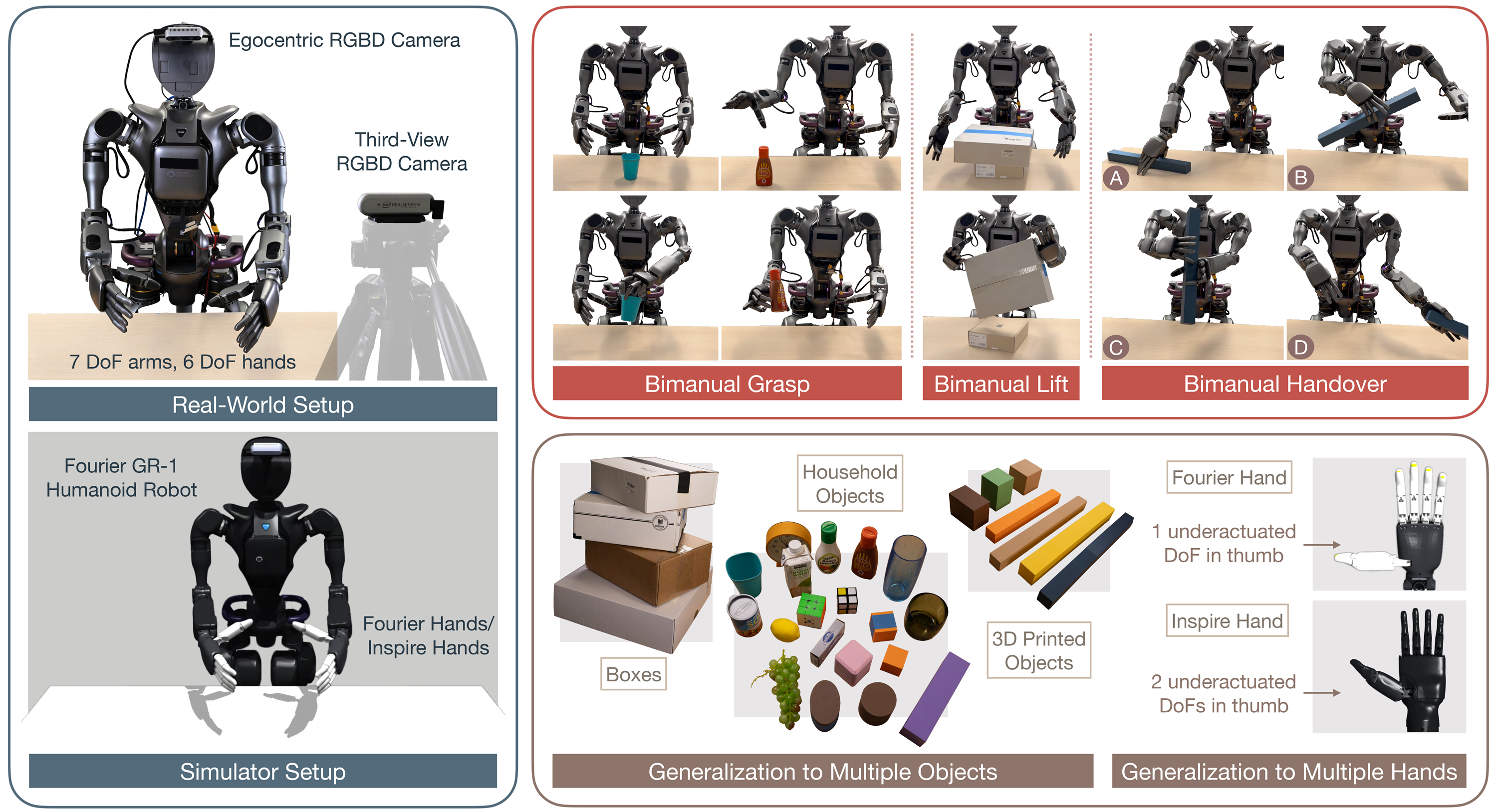
研究背景与挑战
强化学习(Reinforcement Learning)是一种机器学习方法,其核心思想是智能体通过与动态环境交互,基于当前状态选择动作,并根据环境反馈的奖励信号,逐步优化其决策策略。如今强化学习已在多个领域展现出达到甚至超越真人示范的训练效果,但在灵巧机器人操作任务中仍存在局限。其中关键在于灵巧操作(如抓取、搬运、双手交接)通常涉及复杂的接触交互,对人形机器人的感知、控制与学习能力有较高要求。在模拟环境中训练强化学习策略虽然可以高效学习试错,但将这些策略成功迁移到现实环境中面临着诸多挑战。
核心贡献与突破
研究团队提出了一种基于虚拟到现实(Sim-to-Real)强化学习的人形机器人灵巧操作方法,聚焦机器人本体执行多接触点操作任务的核心难点,通过对环境建模、奖励设计、策略学习与感知迁移等四大模块进行分别优化,训练机器人完成灵巧执行接触密集型操作任务。

关键技术
基于视觉的灵巧操作的仿真到现实强化学习流程,四大模块协同工作以实现人形机器人的灵巧操作。
自动化的真实到仿真调优模块:研究团队通过“自动调优(Autotune)”模块加速该建模流程,可在约4分钟内,自动搜索并优化仿真参数与URDF常量,通过对比真实机器人与多套仿真环境的关节跟踪误差,选取最小均方误差的参数组合,使仿真行为逼近真实机器人。同时采用近似物体建模,将物体简化为基本几何形状,平衡训练效率与策略迁移能力。该方案解决了目前机器人领域中存在的两大问题:一是仿真环境与现实环境难以做到精确匹配,直接依赖物理硬件进行训练既成本高昂且风险较大;二是传统的灵巧操作“Sim to Real”工程流程则往往繁复且缺乏通用性。
通用化的奖励设计方案:通过优化了奖励函数,研发团队根据人类操作直觉将复杂操作的奖励函数拆解为“接触目标”和“物体目标”的通用奖励设计方案,设计了一套更易扩展、复用的奖励结构,降低了复杂任务中的奖励工程成本。传统的强化学习的研究往往把奖励视为不变的先验常量,而该方案的奖励设计思路在针对多指灵巧操作等涉及丰富接触的机器人任务中,如何兼顾通用性与高效性提出了更优解。
分治法知识蒸馏方法:研发团队提出两种技术改进方案:第一个是远程操作搜集人类操作的数据作为训练初始状态来降低强化学习算法探索的难度,同时数据采集只需要人类以任务为目标随意操作,减少对数据质量的要求;第二个是采用将复杂任务拆分的方式分别训练子任务,先分别训练专属策略,再将这些专家策略蒸馏为通用策略,提高学习效率及策略泛化能力;有效解决由于探索高维空间时样本复杂度高且奖励稀疏所导致的策略学习速度缓慢问题。
稀疏与稠密特征结合的物体表征:为了减少仿真与现实之间的感知差距,研发团队尝试使用低维的3D物体位置信息与高维的深度图像的组合来表示物体,平衡学习的效率与可迁移性。并且作者对物理参数与视觉成像进行广泛随机扰动,提升策略对真实世界变化的鲁棒性。该方法解决了物体感知的核心问题:物体在形状、尺寸和质量等属性上的高度多样性带来的两难困境——高维表示虽然信息丰富,但与现实的仿真差距较大;低维表示虽易迁移,却难以支撑策略的最优学习。

灵巧性与泛化能力
该实验策略在多种物体上均实现灵巧抓取,包括训练范围之外的全新物体。这种涌现的灵巧操控能力使该策略能够胜任精细指尖操作的高难度抓取任务,例如抓取体积细小且表面光滑的物体。并且即使在面对相同的物体时同一策略也能够产生多样化的抓取模式,这些模式能够根据物体属性和状态的变化自适应调整。

该视频展示机器人练习物品抓取与放置

该视频展示机器人练习双手交接
鲁棒性与恢复能力分析
在实验过程中随机对物体进行干扰:用工具或手部沿随机方向戳、拉、推物体。发现该策略对随机外力具有鲁棒性,且能迅速自我调整以维持连续的策略执行。此外,在外力干扰强烈致使物体掉落的情况下,机器人仍能迅速调整指尖动作并重新抓取,从而延续既定策略,展现出灵活有效的故障恢复能力及卓越的鲁棒性。

在外力干扰物品掉落后,机器人迅速调整策略,重新完成抓取
模拟训练中的动态行为
研究显示,在模拟训练过程中该策略会演化出极具动态性和创造性的动作。虽然这些行为通常利用了模拟器的动力学特性,难以直接迁移到现实环境,但它们仍具有一定的研究价值。

标准传递策略

基于动力学探索的非常规高速传递策略,这种有趣的动态行为为研究提供了新的视角
结论与展望
相关研究构建了人形机器人灵巧操作的全流程Sim-to-Real闭环,为复杂接触式任务提供了可扩展的强化学习框架。通过优化模拟到现实的强化学习,不仅实现了无需人类示范的全关节控制策略迁移,还显著提高了策略的鲁棒性和泛化能力。未来工作需进一步突破硬件限制与长视界任务规划,推动机器人灵巧操作迈向人类水平。
论文链接:Sim-to-Real RL for Vision-Based Dexterous Manipulation on Humanoids
傅利叶支持并推动具身智能的研究探索,通过与全球最头部的科技公司和顶尖科研院校开展交流与合作,加速人形机器人技术的创新与应用,促进AI与物理世界的融合发展。
Contact Us
生态合作:generalrobot@fftai.com
人才招聘:job@fftai.com

